k@laptop:~$ cd ~ # Update the source list k@laptop:~$ sudo apt-get update # The OpenJDK project is the default version of Java # that is provided from a supported Ubuntu repository. k@laptop:~$ sudo apt-get install default-jdk k@laptop:~$ java -version java version "1.7.0_65" OpenJDK Runtime Environment (IcedTea 2.5.3) (7u71-2.5.3-0ubuntu0.14.04.1) OpenJDK 64-Bit Server VM (build 24.65-b04, mixed mode)
k@laptop:~$ sudo addgroup hadoop Adding group `hadoop' (GID 1002) ... Done. k@laptop:~$ sudo adduser --ingroup hadoop hduser Adding user `hduser' ... Adding new user `hduser' (1001) with group `hadoop' ... Creating home directory `/home/hduser' ... Copying files from `/etc/skel' ... Enter new UNIX password: Retype new UNIX password: passwd: password updated successfully Changing the user information for hduser Enter the new value, or press ENTER for the default Full Name []: Room Number []: Work Phone []: Home Phone []: Other []: Is the information correct? [Y/n] Y
ssh 서버랑 클라이언트를 설치합니다.
k@laptop:~$ sudo apt-get install openssh-client openssh-server
그 다음 ssh RSA 키를 생성합니다. Hadoop은 노드들을 관리하기 위해서 ssh 접속을 해야합니다. 여기서는 single-node이기 때문에 localhost에 접속할 수 있도록 설정을 해줘야 합니다. ssh 서버를 구동하고 ssh public key로 인증할 수 있도록 설정하고 ssh 인증서를 등록해 패스워드 입력 없이 접속 할 수 있도록 합니다.
k@laptop:~$ su hduser Password: k@laptop:~$ ssh-keygen -t rsa -P "" Generating public/private rsa key pair. Enter file in which to save the key (/home/hduser/.ssh/id_rsa): Created directory '/home/hduser/.ssh'. Your identification has been saved in /home/hduser/.ssh/id_rsa. Your public key has been saved in /home/hduser/.ssh/id_rsa.pub. The key fingerprint is: 50:6b:f3:fc:0f:32:bf:30:79:c2:41:71:26:cc:7d:e3 hduser@laptop The key's randomart image is: +--[ RSA 2048]----+ | .oo.o | | . .o=. o | | . + . o . | | o = E | | S + | | . + | | O + | | O o | | o.. | +-----------------+ hduser@laptop:/home/k$ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
원하는대로 잘 작동하는 지 테스트해봅니다.
hduser@laptop:/home/k$ ssh localhost The authenticity of host 'localhost (127.0.0.1)' can't be established. ECDSA key fingerprint is e1:8b:a0:a5:75:ef:f4:b4:5e:a9:ed:be:64:be:5c:2f. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts. Welcome to Ubuntu 14.04.1 LTS (GNU/Linux 3.13.0-40-generic x86_64) ...
이제 기본적인 환경 설정은 완료되었고 Hadoop을 설치합니다.
hduser@laptop:~$ wget http://mirrors.sonic.net/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz hduser@laptop:~$ tar xvzf hadoop-2.6.0.tar.gz
Hadoop을 /usr/local/hadoop 디렉토리에 설치하기 위해 파일을 옮기 겠습니다.
hduser@laptop:~/hadoop-2.6.0$ sudo mv * /usr/local/hadoop [sudo] password for hduser: hduser is not in the sudoers file. This incident will be reported.
아래와 같이 에러가 뜬다면 sudo에 hduser를 등록해줘야합니다.
"hduser is not in the sudoers file. This incident will be reported."
hduser@laptop:~/hadoop-2.6.0$ su k Password: k@laptop:/home/hduser$ sudo adduser hduser sudo [sudo] password for k: Adding user `hduser' to group `sudo' ... Adding user hduser to group sudo Done.
이제 hduser가 root 권한을 가졌으니 다시 /usr/local/hadoop 디렉토리에 옮길 수 있습니다.
k@laptop:/home/hduser$ sudo su hduser hduser@laptop:~/hadoop-2.6.0$ sudo mv * /usr/local/hadoop hduser@laptop:~/hadoop-2.6.0$ sudo chown -R hduser:hadoop /usr/local/hadoop
Hadoop 설정을 하도록 하겠습니다. 아래 파일들을 수정해 줘야합니다.
- ~/.bashrc
- /usr/local/hadoop/etc/hadoop/hadoop-env.sh
- /usr/local/hadoop/etc/hadoop/core-site.xml
- /usr/local/hadoop/etc/hadoop/mapred-site.xml.template
- /usr/local/hadoop/etc/hadoop/hdfs-site.xml
1. ~/.bashrc:
먼저 Java가 설치된 경로를 아래 명령을 사용해서 알아내세요.
hduser@laptop update-alternatives --config java There is only one alternative in link group java (providing /usr/bin/java): /usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java Nothing to configure.
이제 ~/.bashrc 에 아래 설정을 추가합니다.
hduser@laptop:~$ vi ~/.bashrc #HADOOP VARIABLES START export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib" #HADOOP VARIABLES END hduser@laptop:~$ source ~/.bashrc
2. /usr/local/hadoop/etc/hadoop/hadoop-env.sh
JAVA_HOME 을 설정합니다.
hduser@laptop:~$ vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
3. /usr/local/hadoop/etc/hadoop/core-site.xml:
/usr/local/hadoop/etc/hadoop/core-site.xml 파일에는 Hadoop이 시작될 때 사용하는 property 값들을 설정해 줘야합니다.
Hadoop에서 사용할 tmp 디렉토리를 생성합니다.
hduser@laptop:~$ sudo mkdir -p /app/hadoop/tmp hduser@laptop:~$ sudo chown hduser:hadoop /app/hadoop/tmp
아래 설절을 <configuration></configuration> 태그 사이에 추가합니다.
hduser@laptop:~$ vi /usr/local/hadoop/etc/hadoop/core-site.xml <configuration> <property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.</description> </property> </configuration>
4. /usr/local/hadoop/etc/hadoop/mapred-site.xml
기본적으로 /usr/local/hadoop/etc/hadoop/ 폴더에 있는 /usr/local/hadoop/etc/hadoop/mapred-site.xml.template 파일을 복사해서 mapred-site.xml을 생성합니다.
hduser@laptop:~$ cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
mapred-site.xml 파일은 MapReduce에서 사용되는 프레임워크를 지정합니다.
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:54311</value> <description>The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-process as a single map and reduce task. </description> </property> </configuration>
5. /usr/local/hadoop/etc/hadoop/hdfs-site.xml
/usr/local/hadoop/etc/hadoop/hdfs-site.xml 파일은 클러스터의 각 호스트마다 설정이 되어야합니다. 호스트 내에서 사용할 namenode 와 datanode 의 디렉토리를 설정하기 때문입니다.
파일을 수정하기 전에 namenode와 datanode 디렉토리를 생성해줍니다.
hduser@laptop:~$ sudo mkdir -p /usr/local/hadoop_store/hdfs/namenode hduser@laptop:~$ sudo mkdir -p /usr/local/hadoop_store/hdfs/datanode hduser@laptop:~$ sudo chown -R hduser:hadoop /usr/local/hadoop_store
이제 파일을 열고 <configuration></configuration> 태크 사이에 아래와 같이 수정해줍니다.
hduser@laptop:~$ vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>1</value> <description>Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. </description> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop_store/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop_store/hdfs/datanode</value> </property> </configuration>
hduser@laptop:~$ hadoop namenode -format DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. 15/04/18 14:43:03 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = laptop/192.168.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.0 STARTUP_MSG: classpath = /usr/local/hadoop/etc/hadoop ... STARTUP_MSG: java = 1.7.0_65 ************************************************************/ 15/04/18 14:43:03 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 15/04/18 14:43:03 INFO namenode.NameNode: createNameNode [-format] 15/04/18 14:43:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Formatting using clusterid: CID-e2f515ac-33da-45bc-8466-5b1100a2bf7f 15/04/18 14:43:09 INFO namenode.FSNamesystem: No KeyProvider found. 15/04/18 14:43:09 INFO namenode.FSNamesystem: fsLock is fair:true 15/04/18 14:43:10 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000 15/04/18 14:43:10 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true 15/04/18 14:43:10 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000 15/04/18 14:43:10 INFO blockmanagement.BlockManager: The block deletion will start around 2015 Apr 18 14:43:10 15/04/18 14:43:10 INFO util.GSet: Computing capacity for map BlocksMap 15/04/18 14:43:10 INFO util.GSet: VM type = 64-bit 15/04/18 14:43:10 INFO util.GSet: 2.0% max memory 889 MB = 17.8 MB 15/04/18 14:43:10 INFO util.GSet: capacity = 2^21 = 2097152 entries 15/04/18 14:43:10 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false 15/04/18 14:43:10 INFO blockmanagement.BlockManager: defaultReplication = 1 15/04/18 14:43:10 INFO blockmanagement.BlockManager: maxReplication = 512 15/04/18 14:43:10 INFO blockmanagement.BlockManager: minReplication = 1 15/04/18 14:43:10 INFO blockmanagement.BlockManager: maxReplicationStreams = 2 15/04/18 14:43:10 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false 15/04/18 14:43:10 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000 15/04/18 14:43:10 INFO blockmanagement.BlockManager: encryptDataTransfer = false 15/04/18 14:43:10 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 15/04/18 14:43:10 INFO namenode.FSNamesystem: fsOwner = hduser (auth:SIMPLE) 15/04/18 14:43:10 INFO namenode.FSNamesystem: supergroup = supergroup 15/04/18 14:43:10 INFO namenode.FSNamesystem: isPermissionEnabled = true 15/04/18 14:43:10 INFO namenode.FSNamesystem: HA Enabled: false 15/04/18 14:43:10 INFO namenode.FSNamesystem: Append Enabled: true 15/04/18 14:43:11 INFO util.GSet: Computing capacity for map INodeMap 15/04/18 14:43:11 INFO util.GSet: VM type = 64-bit 15/04/18 14:43:11 INFO util.GSet: 1.0% max memory 889 MB = 8.9 MB 15/04/18 14:43:11 INFO util.GSet: capacity = 2^20 = 1048576 entries 15/04/18 14:43:11 INFO namenode.NameNode: Caching file names occuring more than 10 times 15/04/18 14:43:11 INFO util.GSet: Computing capacity for map cachedBlocks 15/04/18 14:43:11 INFO util.GSet: VM type = 64-bit 15/04/18 14:43:11 INFO util.GSet: 0.25% max memory 889 MB = 2.2 MB 15/04/18 14:43:11 INFO util.GSet: capacity = 2^18 = 262144 entries 15/04/18 14:43:11 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 15/04/18 14:43:11 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0 15/04/18 14:43:11 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000 15/04/18 14:43:11 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 15/04/18 14:43:11 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 15/04/18 14:43:11 INFO util.GSet: Computing capacity for map NameNodeRetryCache 15/04/18 14:43:11 INFO util.GSet: VM type = 64-bit 15/04/18 14:43:11 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB 15/04/18 14:43:11 INFO util.GSet: capacity = 2^15 = 32768 entries 15/04/18 14:43:11 INFO namenode.NNConf: ACLs enabled? false 15/04/18 14:43:11 INFO namenode.NNConf: XAttrs enabled? true 15/04/18 14:43:11 INFO namenode.NNConf: Maximum size of an xattr: 16384 15/04/18 14:43:12 INFO namenode.FSImage: Allocated new BlockPoolId: BP-130729900-192.168.1.1-1429393391595 15/04/18 14:43:12 INFO common.Storage: Storage directory /usr/local/hadoop_store/hdfs/namenode has been successfully formatted. 15/04/18 14:43:12 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 15/04/18 14:43:12 INFO util.ExitUtil: Exiting with status 0 15/04/18 14:43:12 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at laptop/192.168.1.1 ************************************************************/
hadoop을 실행하기 전에 한번만 hadoop namenode -format 명령이 실행되어야 하며 이후에 다시 실행되면 hadoop 파일 시스템에 있는 모든 데이터는 삭제되니 주의하세요.
드디어 설치된 single node cluster를 실행할 때입니다.
start-all.sh 또는 (start-dfs.sh 와 start-yarn.sh)를 실행해주세요.
k@laptop:~$ cd /usr/local/hadoop/sbin k@laptop:/usr/local/hadoop/sbin$ ls distribute-exclude.sh start-all.cmd stop-balancer.sh hadoop-daemon.sh start-all.sh stop-dfs.cmd hadoop-daemons.sh start-balancer.sh stop-dfs.sh hdfs-config.cmd start-dfs.cmd stop-secure-dns.sh hdfs-config.sh start-dfs.sh stop-yarn.cmd httpfs.sh start-secure-dns.sh stop-yarn.sh kms.sh start-yarn.cmd yarn-daemon.sh mr-jobhistory-daemon.sh start-yarn.sh yarn-daemons.sh refresh-namenodes.sh stop-all.cmd slaves.sh stop-all.sh k@laptop:/usr/local/hadoop/sbin$ sudo su hduser hduser@laptop:/usr/local/hadoop/sbin$ start-all.sh hduser@laptop:~$ start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh 15/04/18 16:43:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [localhost] localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hduser-namenode-laptop.out localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hduser-datanode-laptop.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hduser-secondarynamenode-laptop.out 15/04/18 16:43:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable starting yarn daemons starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-hduser-resourcemanager-laptop.out localhost: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hduser-nodemanager-laptop.out
잘 돌아가고 있는 지 확인해봅시다.
hduser@laptop:/usr/local/hadoop/sbin$ jps 9026 NodeManager 7348 NameNode 9766 Jps 8887 ResourceManager 7507 DataNode
netstat 로도 확인이 가능합니다.
hduser@laptop:~$ netstat -plten | grep java (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 1001 1843372 10605/java tcp 0 0 127.0.0.1:54310 0.0.0.0:* LISTEN 1001 1841277 10447/java tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 1001 1841130 10895/java tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 1001 1840196 10447/java tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 1001 1841320 10605/java tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 1001 1841646 10605/java tcp6 0 0 :::8040 :::* LISTEN 1001 1845543 11383/java tcp6 0 0 :::8042 :::* LISTEN 1001 1845551 11383/java tcp6 0 0 :::8088 :::* LISTEN 1001 1842110 11252/java tcp6 0 0 :::49630 :::* LISTEN 1001 1845534 11383/java tcp6 0 0 :::8030 :::* LISTEN 1001 1842036 11252/java tcp6 0 0 :::8031 :::* LISTEN 1001 1842005 11252/java tcp6 0 0 :::8032 :::* LISTEN 1001 1842100 11252/java tcp6 0 0 :::8033 :::* LISTEN 1001 1842162 11252/java
Hadoop을 stop해 봅시다.
$ pwd /usr/local/hadoop/sbin $ ls distribute-exclude.sh httpfs.sh start-all.sh start-yarn.cmd stop-dfs.cmd yarn-daemon.sh hadoop-daemon.sh mr-jobhistory-daemon.sh start-balancer.sh start-yarn.sh stop-dfs.sh yarn-daemons.sh hadoop-daemons.sh refresh-namenodes.sh start-dfs.cmd stop-all.cmd stop-secure-dns.sh hdfs-config.cmd slaves.sh start-dfs.sh stop-all.sh stop-yarn.cmd hdfs-config.sh start-all.cmd start-secure-dns.sh stop-balancer.sh stop-yarn.sh
stop-all.sh 또는 (stop-dfs.sh 와 stop-yarn.sh) 를 실행하면 우리 머신에서 돌아가고 있는 데몬이 모두 stop됩니다.
hduser@laptop:/usr/local/hadoop/sbin$ pwd /usr/local/hadoop/sbin hduser@laptop:/usr/local/hadoop/sbin$ ls distribute-exclude.sh httpfs.sh start-all.cmd start-secure-dns.sh stop-balancer.sh stop-yarn.sh hadoop-daemon.sh kms.sh start-all.sh start-yarn.cmd stop-dfs.cmd yarn-daemon.sh hadoop-daemons.sh mr-jobhistory-daemon.sh start-balancer.sh start-yarn.sh stop-dfs.sh yarn-daemons.sh hdfs-config.cmd refresh-namenodes.sh start-dfs.cmd stop-all.cmd stop-secure-dns.sh hdfs-config.sh slaves.sh start-dfs.sh stop-all.sh stop-yarn.cmd hduser@laptop:/usr/local/hadoop/sbin$ hduser@laptop:/usr/local/hadoop/sbin$ stop-all.sh This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh 15/04/18 15:46:31 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Stopping namenodes on [localhost] localhost: stopping namenode localhost: stopping datanode Stopping secondary namenodes [0.0.0.0] 0.0.0.0: no secondarynamenode to stop 15/04/18 15:46:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable stopping yarn daemons stopping resourcemanager localhost: stopping nodemanager no proxyserver to stop
다시 Hadoop을 시작하고 웹 인터페이스를 확인해 보겠습니다.
hduser@laptop:/usr/local/hadoop/sbin$ start-all.sh
웹 브라우저로 http://localhost:50070/ 들어가면 Name Node의 웹 UI가 보입니다.
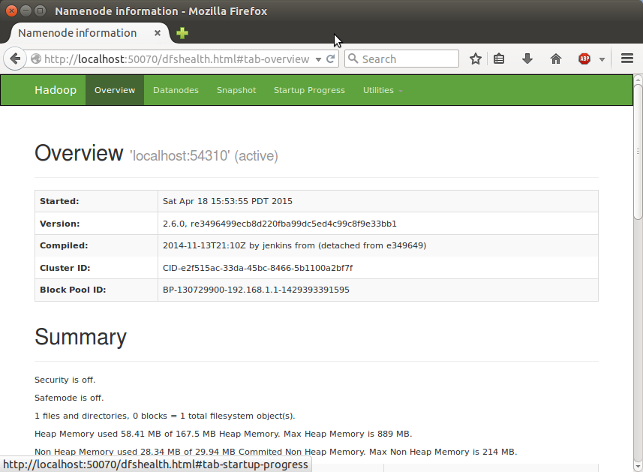
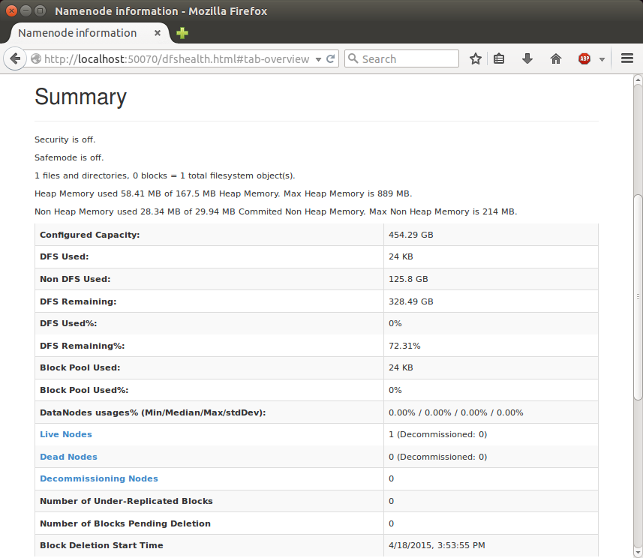
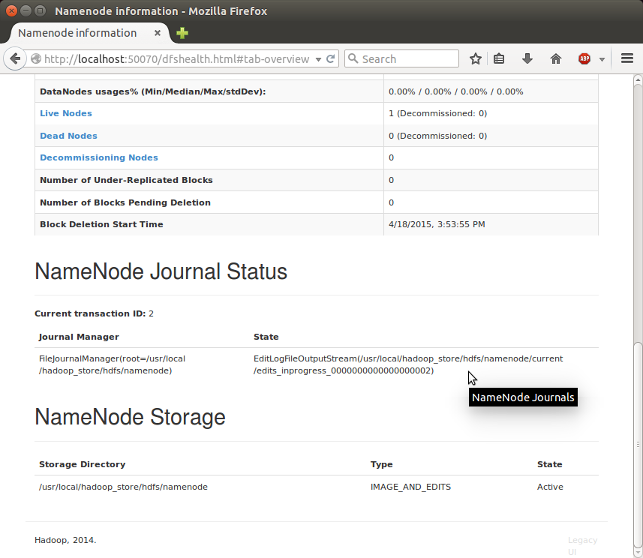
SecondaryNameNode 도 http://localhost:50090 에서 확인할 수 있습니다.
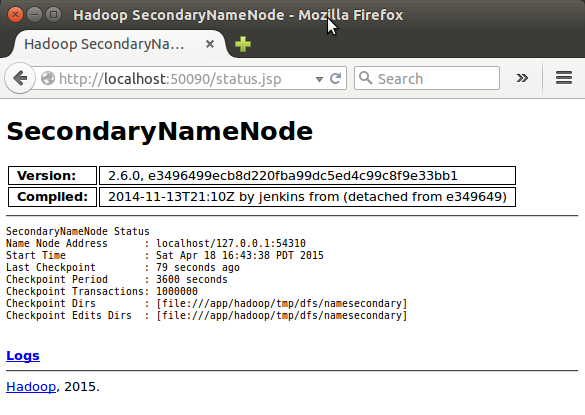
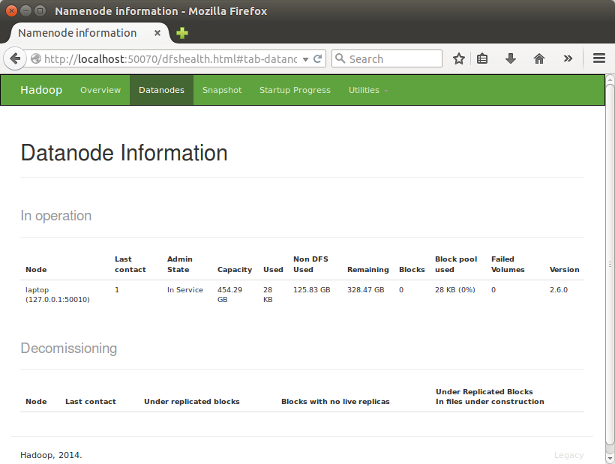
DataNode 도 http://localhost:50070 에서 보실 수 있구요.
수고 하셨습니다. 다음에는 설치된 Hadoop과 연동하여 Spark를 설치하는 것에 대해서 알아보겠습니다. 물론 Hadoop pre-compile된 Spark를 다운받아 설치하셔되 됩니다.
'Machine Learning' 카테고리의 다른 글
| Hadoop 사용 Port (1) | 2016.04.23 |
|---|---|
| Mesos를 Standalone으로 돌리기 (0) | 2016.04.16 |
| Spark 빌드하기 (0) | 2016.04.16 |